| Climber Records - Power Law * |
|
Background
A vast range of natural phenomena are described by a Power Law relationship.1 The following excerpt from reference [1] suffices for an appreciation of the power law's scope.
"The distribution of a wide variety of natural and man-made phenomena follow a power law, including frequencies of words in most languages, frequencies of family names, sizes of craters on the moon and of solar flares, the sizes of power outages, earthquakes, and wars, the popularity of books and music, and many other quantities."
A power law is any polynomial
relationship exhibiting
scale invariance
as described below.
Most commonly one has
| y = f(x) = a xk | (1) |
where a is a constant and k is the scaling exponent. For our purposes the independent variable x is the number of highpointers, or climbers generally; and the dependent variable y is the corresponding value in the relevant records list.2
It is not obvious that climber numbers form the "natural" set of independent variables. It seems perfectly acceptable to also consider values in the relevant records list as the independent set; and climber numbers as depending on them. One of the seven lists studied is analyzed in this fashion.
An alternative to the above formulation is given by integrating (1) with respect to variable x from infinity to x0,
| y = g(x) = a xk+1 / (k+1) | (2a) |
| = A x p | (2b) |
where A = a / (k+1) and p = k+1 and the 0 subscript has been suppressed.
Owing to the often small number of data points for a given narrow range in x-values, the probability density given by Equation (1) often varies wildly. To smooth over this effect, Equation (2b) is used in the detailed calculations, i.e. a cumulative probability distribution describing how many climbers have at least a specified cutoff value in the list.
Scale Invariance
A phenomenon exhibiting scale invariance has the property that multiplying the variable x by a constant factor causes only a proportionate scaling of the function itself, i.e. for Equation (1),
| y = f(cx) = a (cx)k = ck f(x) . | (3) |
Thus scaling by a constant c multiplies the original power law relation by the constant ck. It follows that all power laws with a particular scaling exponent are equivalent up to constant factors, each being a scaled version of the others.
Taking the logarithm on both sides of Equation (2b),
| ln y = ln A + p ln x . | (4) |
Thus a double-logarithmic plot of ln y against ln x yields a straight line of slope p. This simple relationship is the basis for all graphs displayed in the next section.
1
An excellent online reference is
available at wikipedia.org.
2
y is an
unnormalized
probability density.
Data and Graphs
Seven lists are selected as representive of both the county highpoint FRL ("Front Runner Lists") and the prominence-based lists available at peakbagger.com.
|
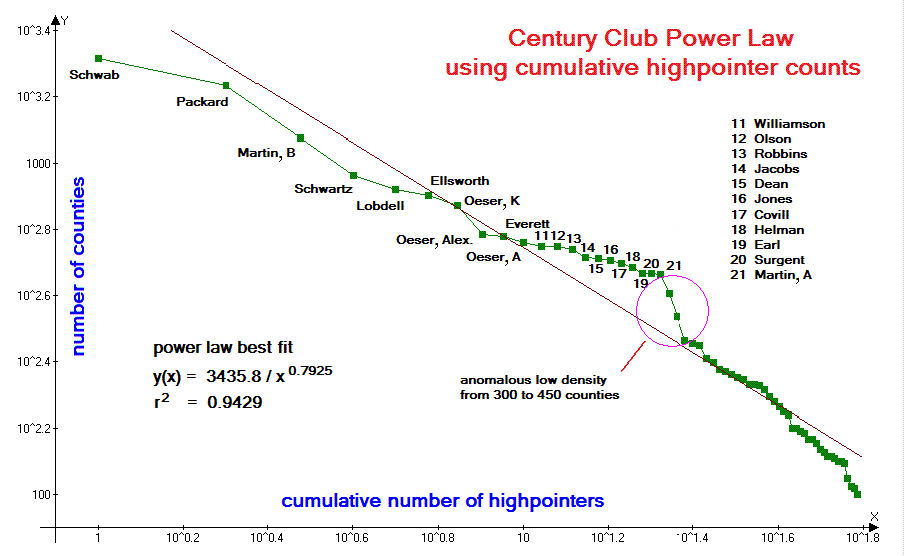
| Figure 1 (Click for the actual graph.) |
|
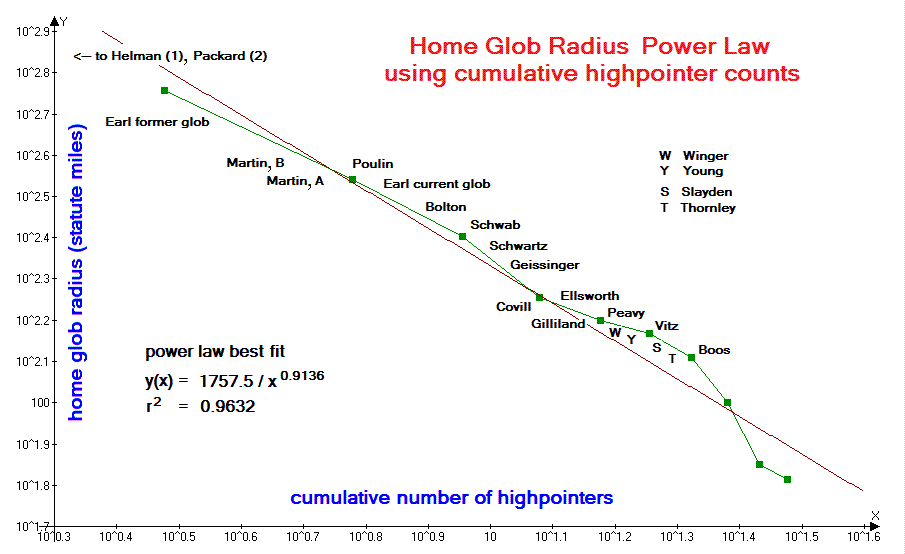
| Figure 2 (Click for the actual graph.) |
|
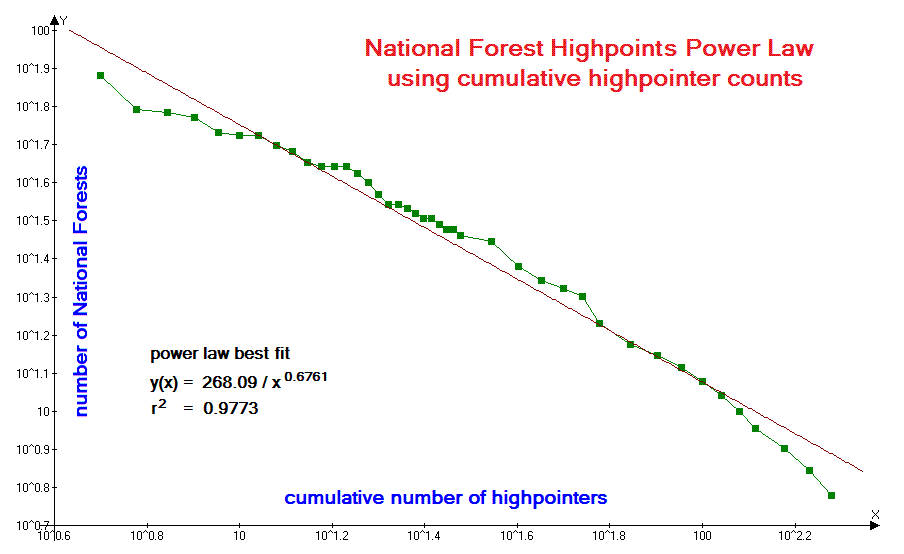
| Figure 3 (Click for the actual graph.) |
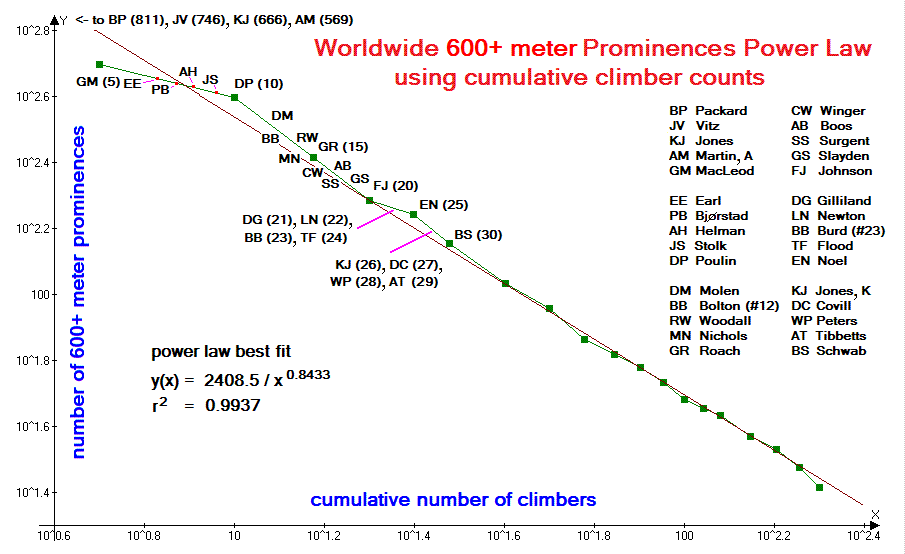
|
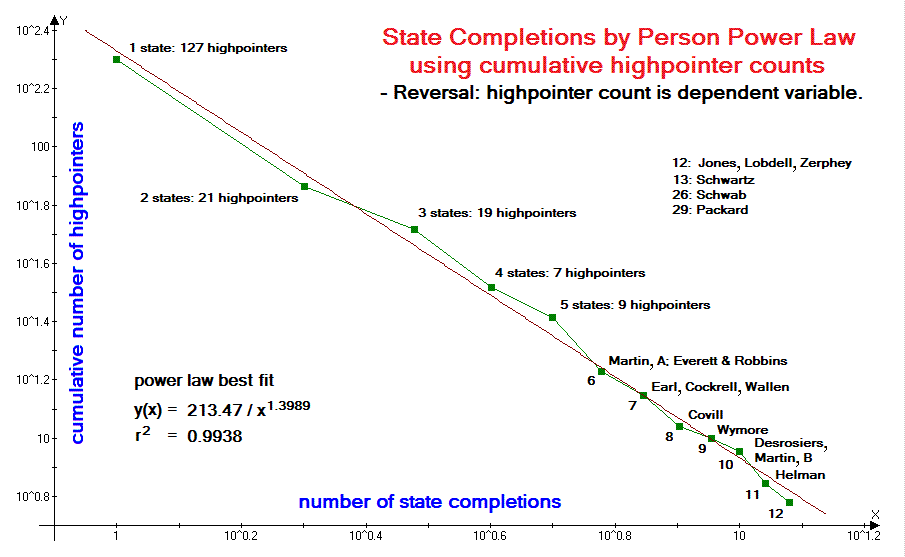
| Figure 4 (Click for the actual graph.) |
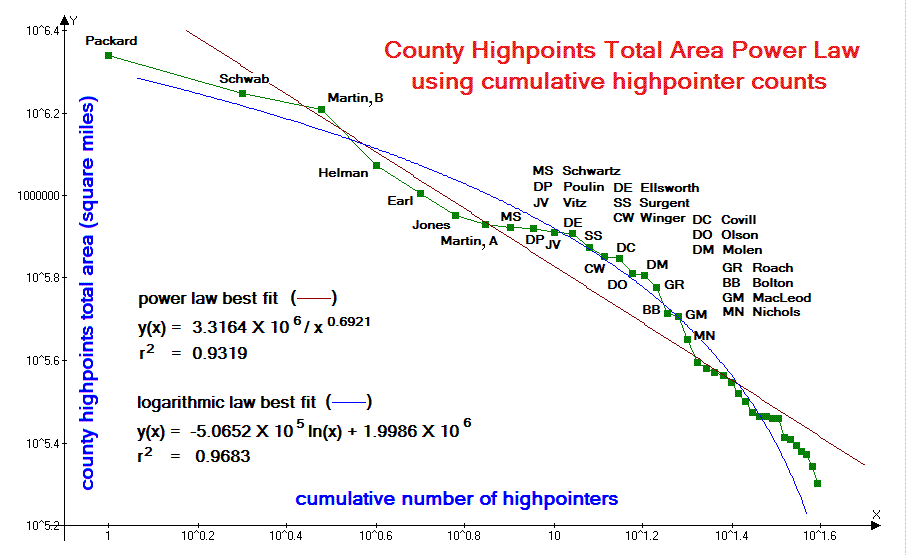
|
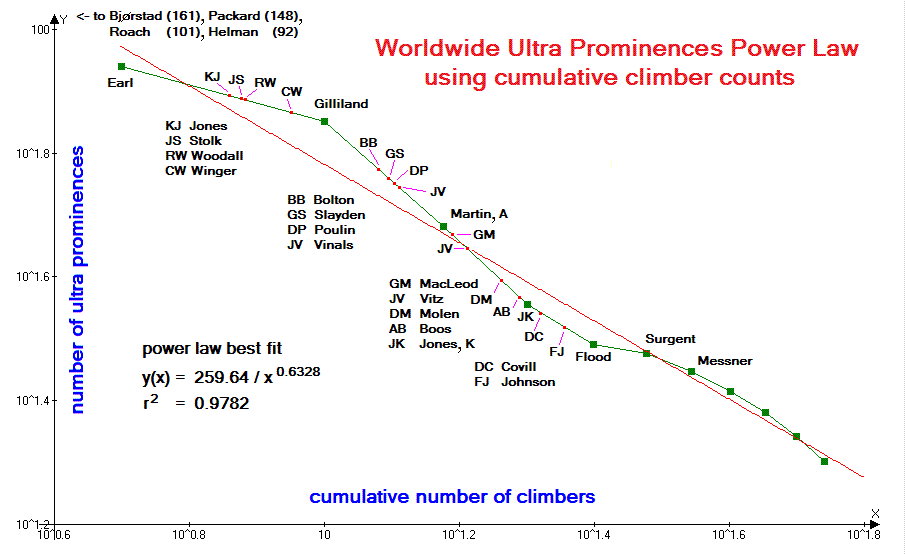
| Figure 5 (Click for the actual graph.) |
|
| Figure 6 (Click for the actual graph.) |
|
| Figure 7 (Click for the actual graph.) |
Lists are graphed and analyzed using values from March 13 and 15, 2011. There is no reason to suspect that the analysis and/or interpretation qualitatively depend on the exact dates.
For each list the least-squares best-fit to numerous functional forms is obtained; including, in addition to a power law relationship the following other types:
linear (y = ax + b), hyperbolic (y = a/x + b), logarithmic (y = a ln x + b), exponential (y = a bx) and n-th degree polynomial. Of these, only a power law relationship results in a straight-line plot when graphed, as performed, on double-logarithmic axes.
3
The national forest highpoint
list currently employed
is incomplete,
requiring research to make it definitive.
4
In the U.S.A. the corresponding cutoff value is 2,000 feet (609.6 meters).
This difference only shifts climber's peak counts without implications for a
power law relationship.
5
The latest manually-updated list is used because the majority of
state completers
have not acquired accounts to automatically log their accomplishments.
6
Internationally an ultra is any peak with at least 1,500 meters
(4,921 feet) of topographic prominence.
The corresponding U.S.A. cutoff value is 5,000 feet (1,524 meters).
This difference only shifts climber's peak counts without implications for a
power law relationship.
Discussion
General
Examination of Figures 1-7 reveals that, in all cases a power law fit (straight line) qualitatively reproduces the data. In all cases the correlation coefficient r2 exceeds 0.93 and with a mean value of 0.9687. For the worldwide 600+ meter prominence list (Figure 4) and state completions by person list (Figure 5) r2 is remarkably close to the 1.00 value of a perfect correlation - 0.9937 and 0.9938 respectively.
With each data set, the power law fit, as measured by r2 is superior to the fits using linear, hyperbolic, logarithmic and exponential functions.7 The sole exceptions (see below) are with the Century Club data (Figure 1) and total county area data (Figure 6), for which logarithmic fits yield higher r2 values.
In the Century Club set (Figure 1) this arises from a single, anomalous low-density of highpointers in the 300-450 county range that, owing to the convexity it creates in the overall curve, is more closely matched by a logarithmic fit. Examination of previous Century Club listings shows no such anomaly, and it is anticipated to vanish once several highpointers with 200-300 counties enter that range.
In the total county area set (Figure 6) the best-fit to a logarithmic function is shown as a blue curve. It is a closer fit than the power law because of the peculiar shape of the graphed data: one that has a "bulge" from about 8 to 20 highpointers ("MS" to "MN"); followed by a rapid dropoff in total area which falls under the straight line. It is unknown whether these two sections (bulge and rapid descent) are reproducible phenomena that persist over time.
With reference to the Century Club data (Figure 1), counties in the eastern U.S.A. are generally easier to "acquire" than those in the mountainous western states, with several possible in a single waking cycle. Therefore eastern highpointers have an advantage amassing large county numbers. It would be instructive to perform separate analyses for eastern and western contingents.
However the most productive of this county highpointing species, currently Bob Schwab and Bob Packard, have globs that connect their eastern and western accomplishments - so confounding any attempt at assigning them to just the eastern or western group.8 Furthermore, the northeastern list of 300 counties has been completed by several people - and, as described below this makes the corresponding graph top-heavy and so incapable of supporting a power law relationship.
The home glob radius record set (Figure 2) contains the opposite effect - here, the large size of western counties provides an advantage to western county highpointers. Indeed, the first eight entries represent home globs in the western states. It would be interesting to perform a separate analysis for just "eastern globs".
Total county areas (Figure 6) also favor the western county highpointer, and for the same reason. However the same uber-highpointers noted above confound any attempt at categorizing highpointers into eastern and western subspecies for separate analyses.
U.S.A. national forest highpoints (Figure 3) and state completions by person (Figure 5) are discussed in later subsections.
7
For n data points it is possible to exactly fit a polynomial expression of
degree n-1. Validity of Fits
There are many ways to identify a power law relationship in data.
Several of them are described in reference [1], including graphical methods
(such as employed here), use of the cumulative distribution (also employed here),
binning methods (which can result in undesired bias), and use of a
maximum likelihood estimator
to obtain a
statistically unbiased
power law exponent p of Equation (2b).
More important, though, is determining the validity of a presumed
power law formulation in the first place. Demonstrating that data indeed follow a
power law relation requires more than just fitting a model to the data.
Alternative functional forms may appear to follow a power-law form for some extent -
and yet, when the data is extended to its uppermost and/or lowermost bounds it may
be found that scale invariance is not forthcoming.
Thus it is easily concluded from the total county area data of
Figure 6
that a logarithmic law might exist, i.e.
simply because the resulting curve-fit is slightly improved from a power law fit.
Another example is provided by the Century Club graph of
Figure 1
wherein an anomalous low climber density (at 300-450 counties) results in a better fit using the
logarithmic function. Both examples have been discussed in the previous subsection.
How is one to "prove" the truthfullness of an assumed functional form?
How close must a straight line be for it to be called a valid formulation?
Just this: What is the probability that seven of seven
climbing record sets all appear to follow a power law relationship
(0.93 < r2 < 1.0) by sheer coincidence?
Choice of Independent Variable
It is "natural" to let the number of peaks climbed etc ... be a function of how many
climbers have at least that value in their resumé. However it is equally valid to let the
number of peaks be the independent variable, and the number of climbers be dependent on it.
This concept may seem unintuitive, yet results in certain favorable outcomes when graphing
the data. It is certainly a valid concept, as seen by solving Equation (2b) for x
in terms of y. There results a power law relationship with a straight line plot
on double-logarithmic axes.
Thus in
Figure 5
there is just one data point per given value of the
independent variable, e.g. 73 highpointers with at least 2 completed states.
Were one to graph this state completions by person records list using highpointer count
as the independent variable, there would be dozens of cumulative highpointer data points
(x-coordinate) all with the same minimum number of completed states (y-coordinate).
The resulting graph is both visually unappealing and makes it difficult to decide
which data points to include - or which to exclude while differentially weighting the
included points.9
9
Differential weighting seems reasonable: should every highpointer with a single Limiting Behavior
The asymptotic behavior of these climber-based graphs do NOT follow a power law.
At the very "lower end" lie the vast majority of people having zero climbing accomplishments.
There likely follows a small fraction with one summit that was reached - perhaps by chance
in driving there. A smaller fraction still have two peaks to their credit.
It is conceivable that this low-end climber count is described by a
Poisson distribution.
At the "upper end" some lists have been "maxed-out" such that no "skinny tail" exists,
i.e. county highpoint
APEX peaks (20 maximum)
and number of states in a glob (48 maximum).
Therefore climber's peak numbers etc... do not reflect true scale invariance;
and as such the power law concept is limited in scope to a narrow range - and even then only for
peak lists and records categories that have never been completed by any one person.
Climber Intention
Many climbers select peaks because they are on specific lists -
with multiple list membership being a most attractive bargain for visiting their summits.
Thus the author intentionally seeks ultra prominence mountains when traveling abroad
to maximize the perceived benefit on a limited time budget. As a result, the number of
ultra summits climbed is disproportionately represented relative to summits of lesser
topographic prominence.
Does this penchant for specific summits alter the analysis? Examination of
Figure 3
for U.S.A. national forest highpoints suggests not: nobody is currently pursuing this list
for its own sake, with counts arising by happy coincidence from having climbed list members
for entirely different reasons. Yet the graph closely follows the straight line indicative
of a power law relationship.
Hence the n-degree polynomial fit is always superior,
as measured by r2, to the other
functional forms tested. This is no consolation as the individual terms have little or no
physical significance. Furthermore, in general it is preferable to fit data
using the least
possible number of parameters - and as achievable using the two-parameters of a
power law relationship. When two parameters can describe dozens of data points
it is likely that they have some useful physical interpretation.
8
In addition Bob Schwab's
Midwestern USA accomplishments
render it
unsatisfactory to describe him as an "eastern" or a "western" county highpointer.
y = a ln x + b
(5)
state completion be individually accorded the same degree of importance as that one
highpointer leading the pack with 29 states to his credit? Likely not.
This issue is avoided by reversing the roles of list value and cumulative highpointer count.
Conclusion
The reader must decide if the analysis suggests that climber accomplishment is modeled by a set of power law expressions that differ from list to list only in a pair of parameters.
In one sense it is a shame to pigeonhole such an inherently enjoyable pursuit using statistical methods developed for science and economics - in essence claiming that, once summed over dozens of people their collective efforts are mathematically predictable just as much as their height and intelligence distributions.
This work does not, and cannot address such issues. That written, it is not the author's intention to demean or somehow lessen the personal significance of climbing through demonstration that it is describable, in some small degree, as an inevitable result of algebra and statistics.
It would be most interesting if a more advanced study were to conclude that peak lists differ in the functional form that most closely matches their respective data, e.g. that area-based lists are logarithmically distributed.
| home page | Front Runner Lists |